Tencent ramps genAI world building with HY-World 2.0


Tencent's HY-World 2.0 matters because it is trying to solve a more useful problem than most recent world model demos. Instead of generating a video that looks interactive for a minute and then disappears, it aims to generate or reconstruct a persistent 3D scene from text, a single image, multi-view images, or video.
In the paper's own framing (PDF), the system unifies two tasks that are often split, world generation from sparse inputs and world reconstruction from richer visual inputs.
That makes it much more relevant to game development, robotics simulation and digital-twin-style environment mapping than the now-familiar category of impressive but disposable AI clips. Tencent itself describes it as the first open-source state-of-the-art 3D world model. It's a bold claim, but one that reflects how few systems in this category produce actual geometry rather than video.
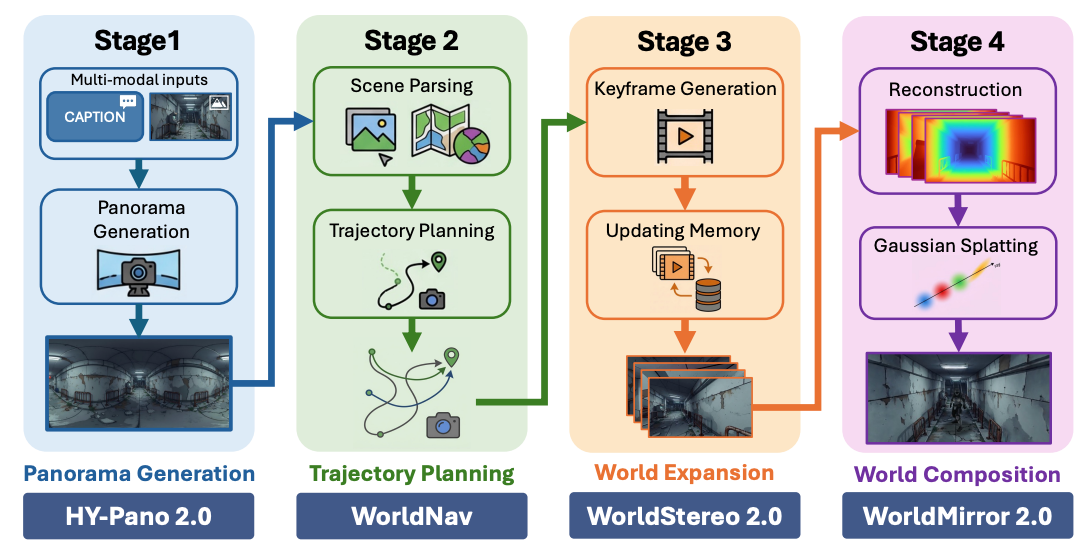
Technically, HY-World 2.0 is a four-stage pipeline.
- First, HY-Pano 2.0 turns text or an image into a 360-degree panorama.
- Second, WorldNav plans trajectories through that space, using geometry and semantic parsing to decide where a virtual camera or agent should move.
- Third, WorldStereo 2.0 expands the world by generating additional views along those trajectories while trying to preserve multi-view consistency.
- Fourth, WorldMirror 2.0 — a roughly 1.2-billion-parameter feed-forward model — reconstructs and composes the final 3D representation, producing outputs such as 3D Gaussian splats, point clouds and meshes.
Tencent also adds WorldLens, a renderer and runtime layer for first-person or third-person exploration with lighting and collision handling.
The most important claim here is not simply "it makes 3D." It is that HY-World 2.0 outputs editable, persistent 3D assets rather than pixel videos.
Tencent's GitHub README explicitly says those assets can be imported into tools and engines such as Blender, Unity, Unreal Engine and Nvidia's Isaac Sim platform, and contrasts that with video world models that suffer from flicker, weak controllability and per-frame inference costs.
The paper itself is slightly more conservative, saying the framework produces 3D world representations and is compatible with standard computer graphics pipelines. That distinction matters: the paper supports the broad architecture; the more product-like workflow claims come from Tencent's README.
The benchmark story is also stronger than pure marketing, though it still needs careful reading.
- On panorama generation, the paper says HY-Pano 2.0 achieves the best scores on the majority of metrics across text-to-panorama and image-to-panorama tasks, and ranks first on all five image-to-panorama metrics reported.
- On world expansion, WorldStereo 2.0 posts the highest point-cloud F1 and AUC scores across the paper's single-view reconstruction benchmarks, including Tanks-and-Temples and MipNeRF360, and its camera-control results beat the listed baselines on the error metrics.
- On reconstruction, the upgraded WorldMirror 2.0 is presented as improving resolution robustness and geometric prediction quality across several benchmarks. Those are real technical claims, and the paper publishes numbers for them.
So what can this actually be used for today? The clearest use case is environment ideation and pre-production. If a team can go from a text prompt or concept image to a navigable scene with extracted geometry, that is useful for greyboxing maps, exploring mood and layout, testing traversal, building quick background spaces, or producing rough digital twins from casual video capture.
Tencent is also explicit that the extracted meshes can act as collision proxies, and the paper says those meshes are simplified to support scene loading and interactive use. That makes HY-World 2.0 feel less like concept art generation and more like an early pipeline for spatial prototyping.
It is also fair to say the system is promising for robotics and embodied simulation, because that is one of the applications the authors themselves name. WorldMirror 2.0 is designed to reconstruct depth, normals, camera parameters, point clouds and 3DGS attributes in a single forward pass from multi-view images or video, and the full framework is pitched as useful for robotics simulation and environment mapping as well as game development. That is important because these are settings where "roughly correct and navigable" can be valuable even when the assets are not final-art quality.
But there are clear limits. First, the open-source release is not yet complete. Tencent says the technical report is out and WorldMirror 2.0 code and checkpoints are available, but the full world-generation inference stack — HY-Pano 2.0, WorldNav and WorldStereo 2.0 — are still marked "coming soon." So the headline open-source world model is true only in a partial sense right now. The public can inspect the architecture and use some components, but not yet reproduce the whole text-to-world pipeline end to end.
Second, this is not yet a frictionless creator product. The paper's runtime analysis reports that one full world generation takes roughly 12 minutes on NVIDIA H20 GPUs. That is fast for research infrastructure, but it is not yet the kind of latency or hardware profile that turns world generation into a mass-market creator feature inside every consumer tool. The H20, notably, is the NVIDIA variant approved for export to China, capable hardware, but not the top of the current lineup. This is much closer to a studio or lab workflow than a Roblox-style instant build button.
Third, some of the splashiest claims still need caution. The comparison with the closed-source model Marble is presented qualitatively using the same inputs, and Tencent says its system is more faithful to those conditions and preserves detail and geometry better. That is interesting, but it is not the same thing as an independent leaderboard win.
More broadly, nothing in the report shows HY-World 2.0 automatically delivering final gameplay logic, production-ready materials, authored quest spaces, or optimized shipped-game environments. What it does show is a strong route to scene generation, scene reconstruction and interactive exploration. That is already meaningful. It just is not the same as replacing the full environment art and design pipeline.